
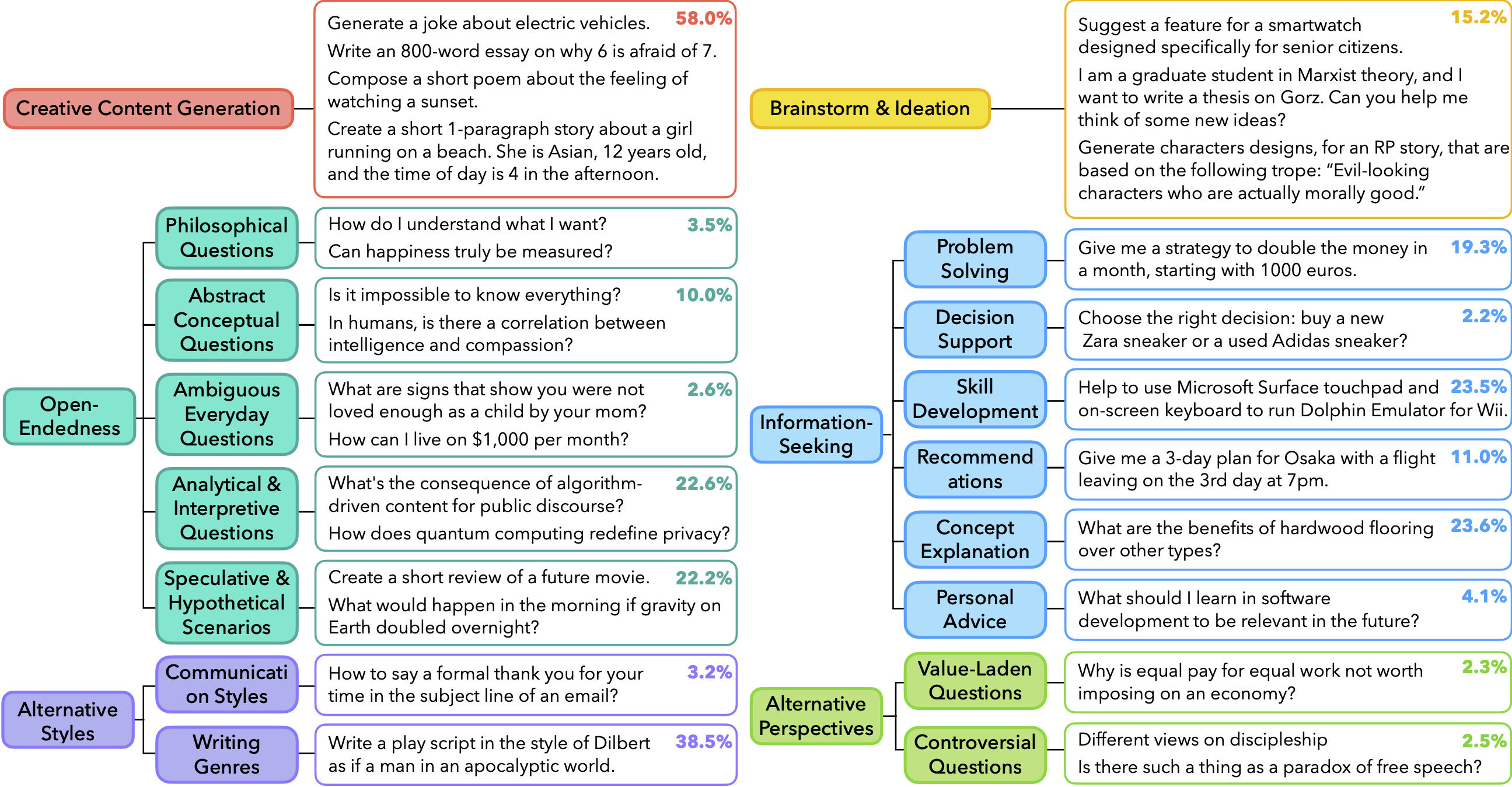
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
This paper introduces Infinity-Chat, a large-scale dataset of 26,000 diverse real-world user queries designed to evaluate language model (LM) output diversity. It presents the first comprehensive taxonomy for classifying open-ended prompts into six categories, revealing a concerning Artificial Hivemind effect in LM responses, where both intra-model repetition and inter-model homogeneity dominate. The study highlights how LMs often fail to capture diverse human preferences in open-ended generation, despite high-quality outputs. Infinity-Chat provides a crucial resource for understanding and mitigating the long-term risks of homogenized thought in AI systems.
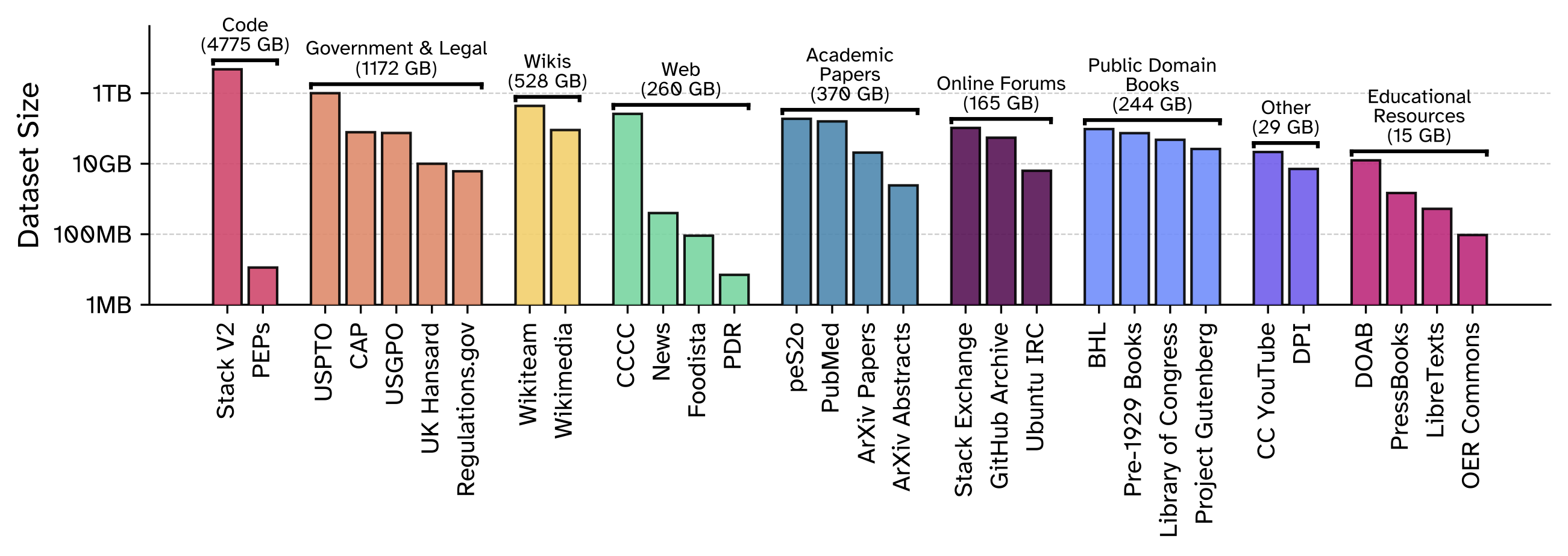
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
This work introduces Common Pile v0.1, an 8TB dataset of openly licensed text curated to support ethical and transparent training of large language models. Spanning 30 diverse sources from research papers to audio transcripts, enabling high-quality model development without relying on unlicensed content. Two 7B-parameter models trained on the dataset, Comma v0.1-1T and Comma v0.1-2T, match the performance of models like LLaMA 1 and 2. All data, code, and model checkpoints are publicly released, setting a new standard for open and responsible AI research.
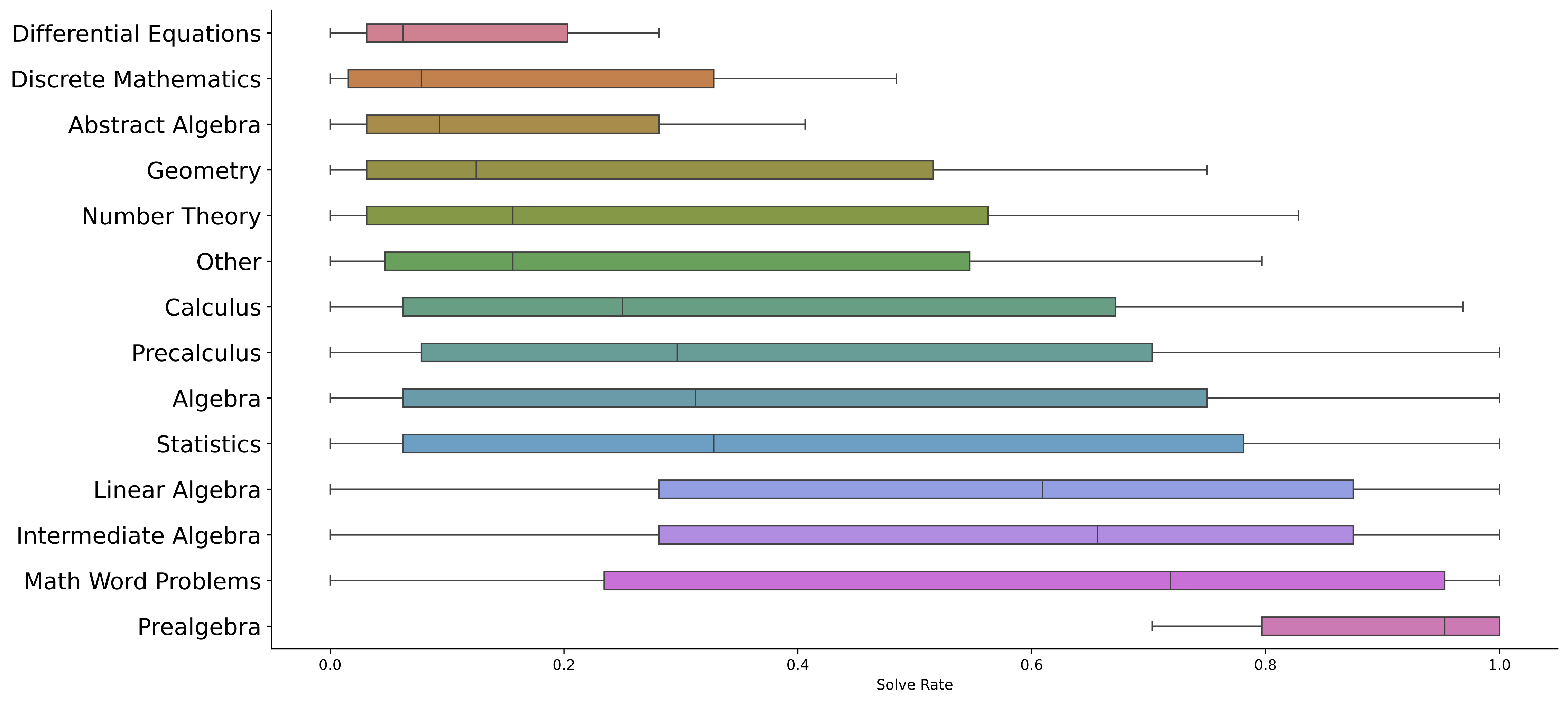
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Big-Math is a dataset of over 250,000 high-quality math questions designed for reinforcement learning (RL) research. Unlike existing datasets that often prioritize either quality or quantity, Big-Math bridges this gap by offering a large collection of rigorously curated problems with verifiable answers. It includes a diverse range of problem domains and difficulty levels, making it suitable for models of varying capabilities. Additionally, Big-Math-Reformulated introduces 47,000 multiple-choice questions reformulated as open-ended problems. This dataset provides a robust foundation for advancing reasoning in large language models (LLMs).
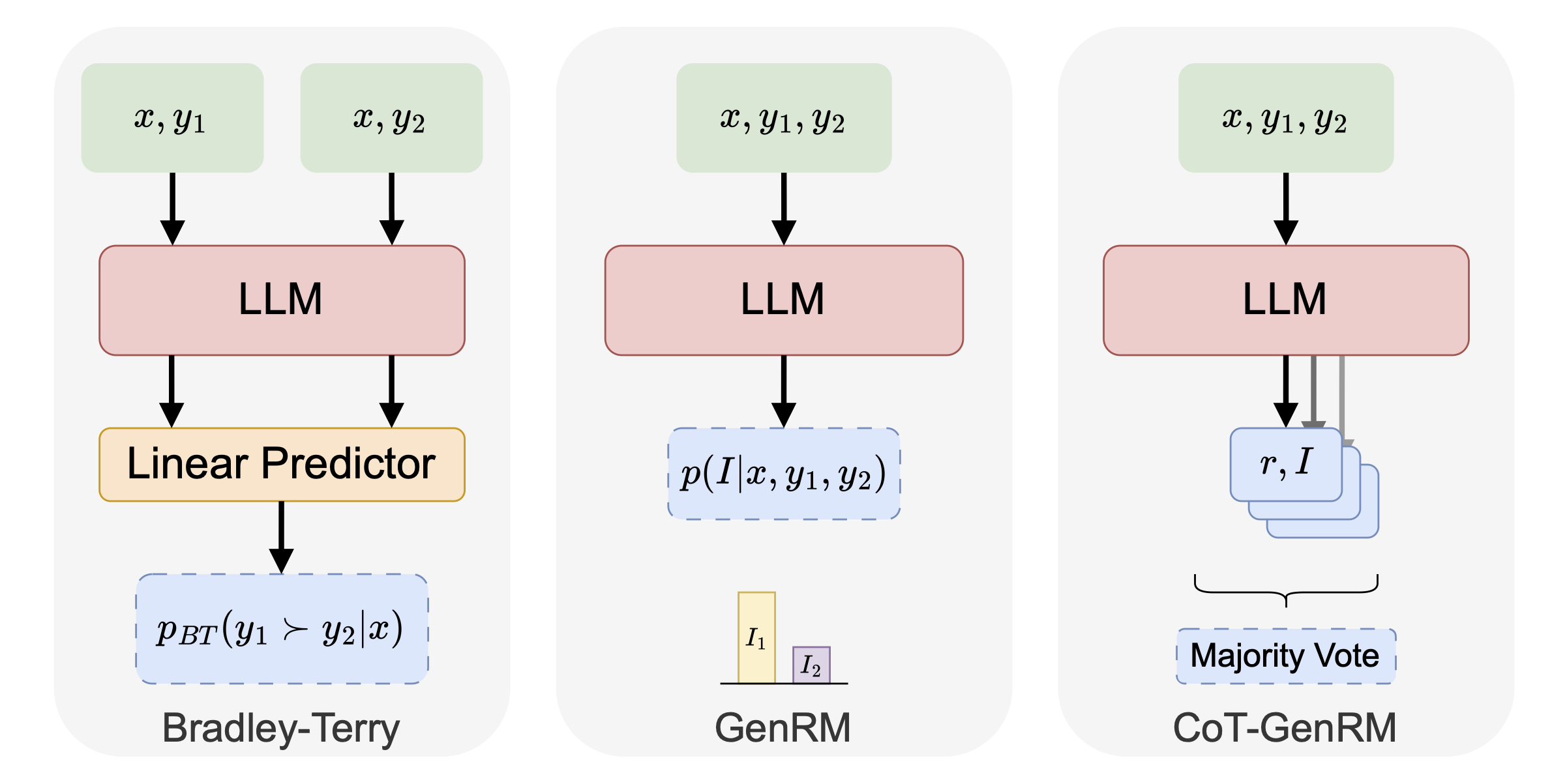
Generative reward models
This work introduces GenRM, an iterative algorithm that combines Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) to improve the quality of synthetic preference labels. While synthetic preferences generated by LLMs have been shown to misalign with human judgments, GenRM trains an LLM on self-generated reasoning traces, aligning synthetic preferences with human preferences. The approach outperforms existing models, achieving comparable accuracy to Bradley-Terry reward models on in-distribution tasks, while significantly surpassing them on out-of-distribution tasks. The results highlight the potential of this hybrid approach for enhancing the effectiveness of synthetic feedback in RL.
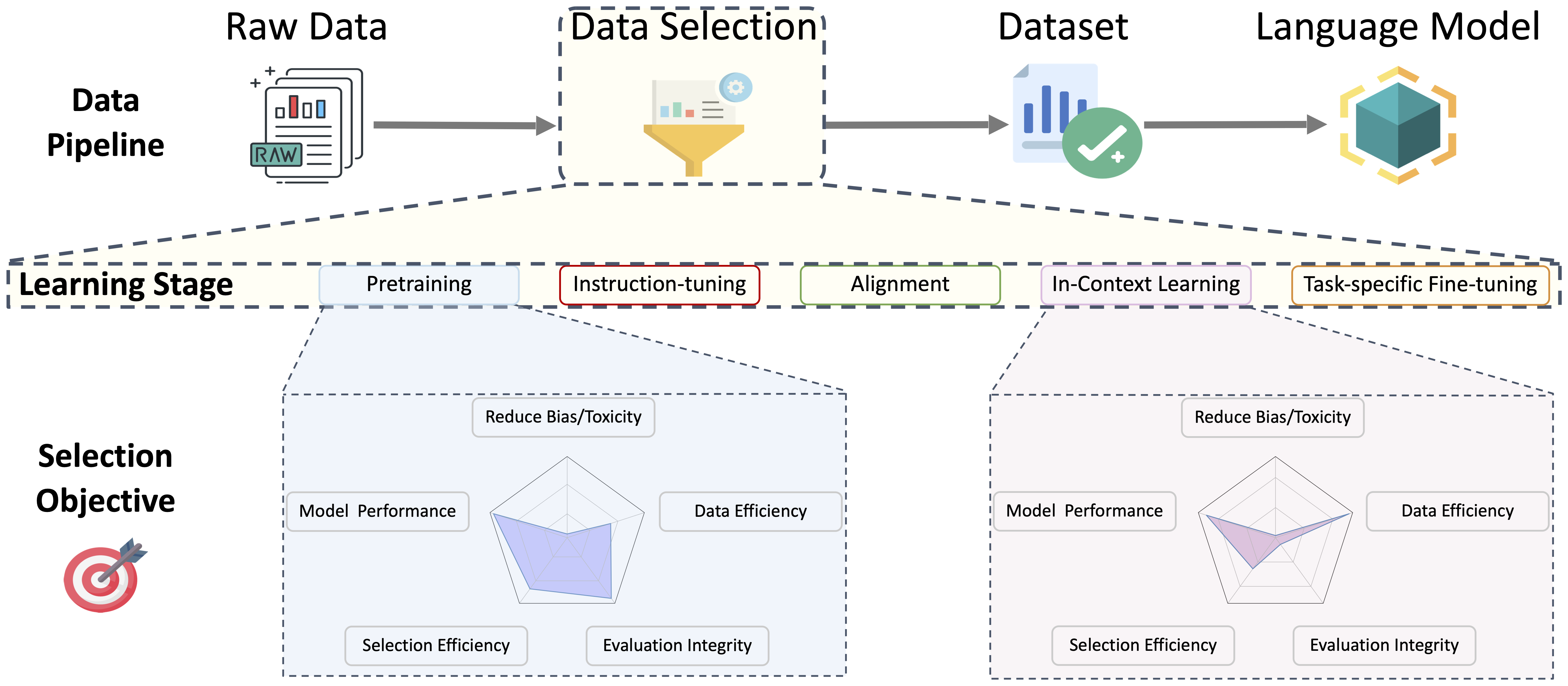
A Survey on Data Selection for Language Models
This work provides a comprehensive review of data selection methods for training large language models (LLMs), an area crucial for improving training efficiency and reducing environmental and financial costs. It presents a taxonomy of existing approaches, highlighting the challenges and opportunities in selecting high-quality data for model pre-training and post-training. By mapping out the current landscape and identifying gaps in the literature, this review aims to accelerate progress in the field, offering valuable insights for both new and experienced researchers. The paper also proposes promising directions for future research to address these gaps.
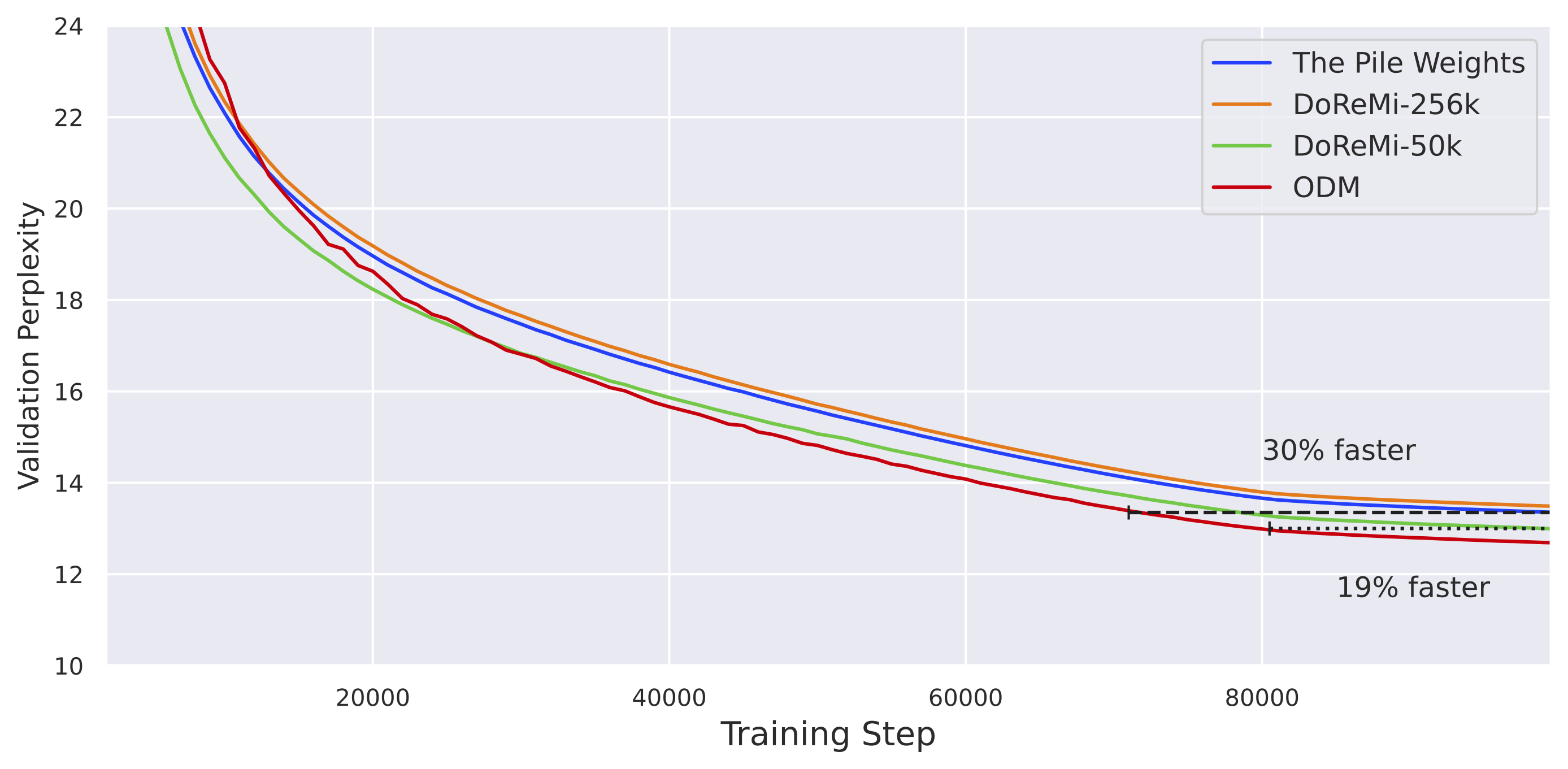
Efficient Online Data Mixing For Language Model Pre-Training
This work introduces Online Data Mixing (ODM), an efficient algorithm that combines data selection and data mixing to optimize the pretraining process of large language models. Unlike traditional methods that use fixed mixing proportions, ODM adapts these proportions dynamically during training, improving computational efficiency. The approach, based on multi-armed bandit algorithms, reduces training iterations by 19%, achieves superior performance on the 5-shot MMLU benchmark (1.9% relative accuracy gain), and adds minimal extra time to pretraining. This method addresses the inefficiencies of existing data selection approaches, making it a promising advancement for large-scale model training.
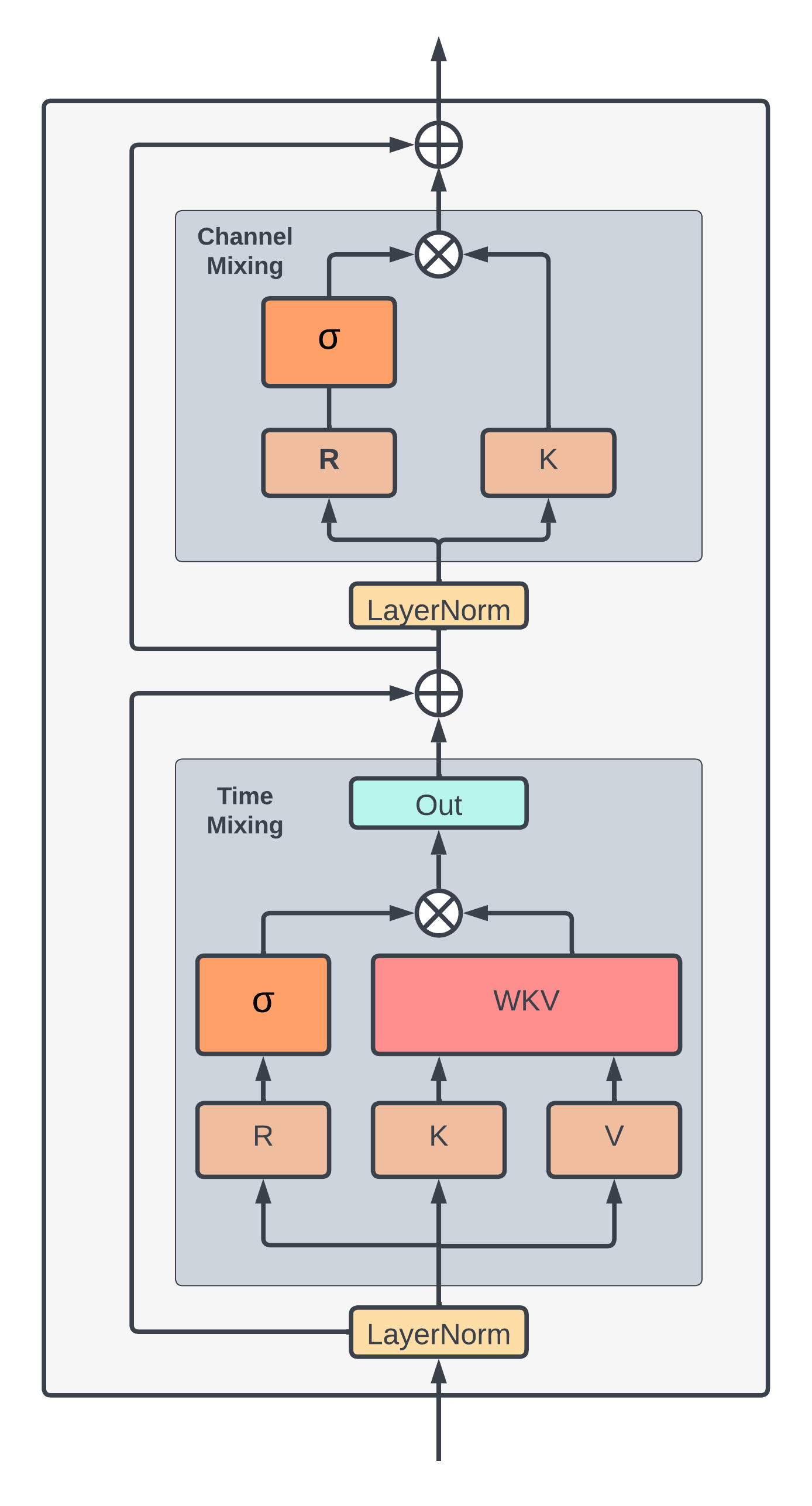
RWKV: Reinventing RNNs for the Transformer Era
This work introduces RWKV, a new architecture that combines the strengths of recurrent neural networks (RNNs) and transformers. RWKV maintains the sequential processing of RNNs while incorporating the attention mechanism of transformers, resulting in a model that is both efficient and effective for long-context tasks. The architecture is designed to be simple and scalable, achieving state-of-the-art performance on various benchmarks while being computationally efficient. RWKV's design allows it to handle long sequences without the quadratic complexity of traditional transformers, making it a promising alternative for large language models.
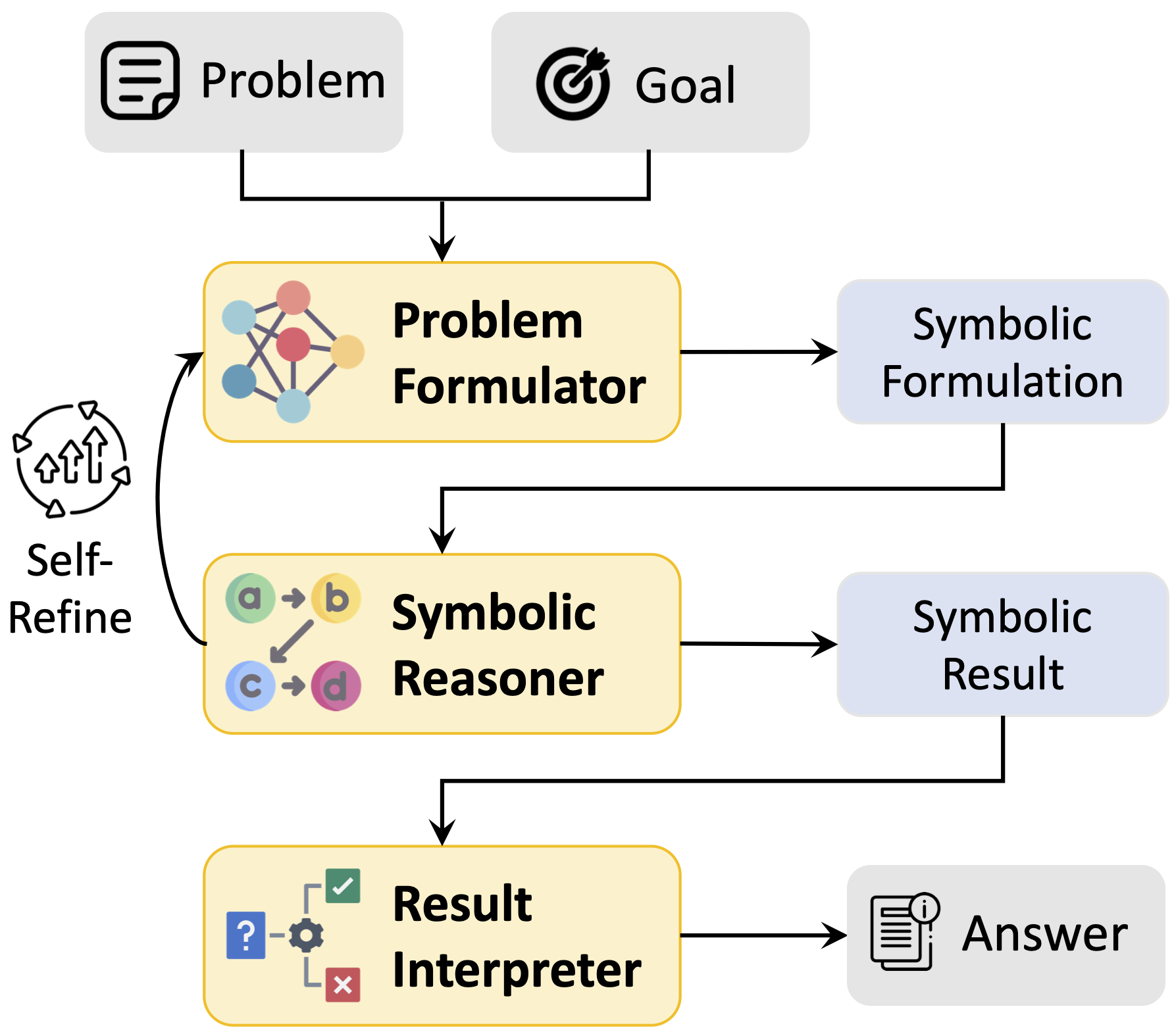
Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning
This work introduces Logic-LM, a framework that combines large language models with symbolic solvers to tackle complex logical reasoning tasks more accurately. By translating natural language into formal logic and using a self-refinement loop guided by feedback, Logic-LM significantly outperforms traditional LLM approaches—achieving up to 39.2% improvement. The approach sets a new direction for integrating statistical and symbolic methods in AI.
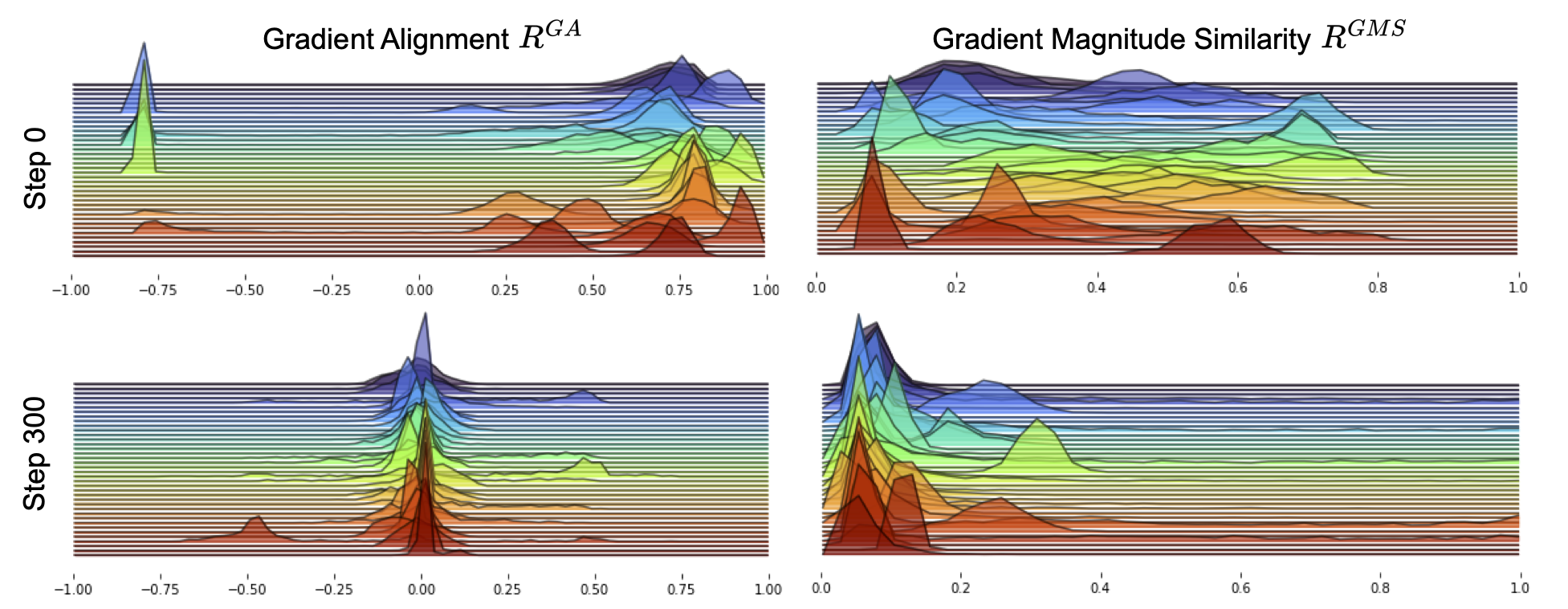
Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data
In this work, we study Few-shot Learning with Auxiliary Data (FLAD), a paradigm that improves generalization in few-shot learning by incorporating auxiliary datasets. Unlike previous methods, which scale poorly with the number of auxiliary datasets, the proposed algorithms, EXP3-FLAD and UCB1-FLAD, overcome this limitation by achieving computational complexity independent of dataset size. Motivated by multi-armed bandit algorithms, we combine exploration and exploitation into algorithms that outperform existing FLAD methods by 4% and enable 3-billion-parameter language models to surpass the performance of GPT-3 (175 billion parameters). This work suggests that more efficient mixing strategies for FLAD can significantly enhance few-shot learning.
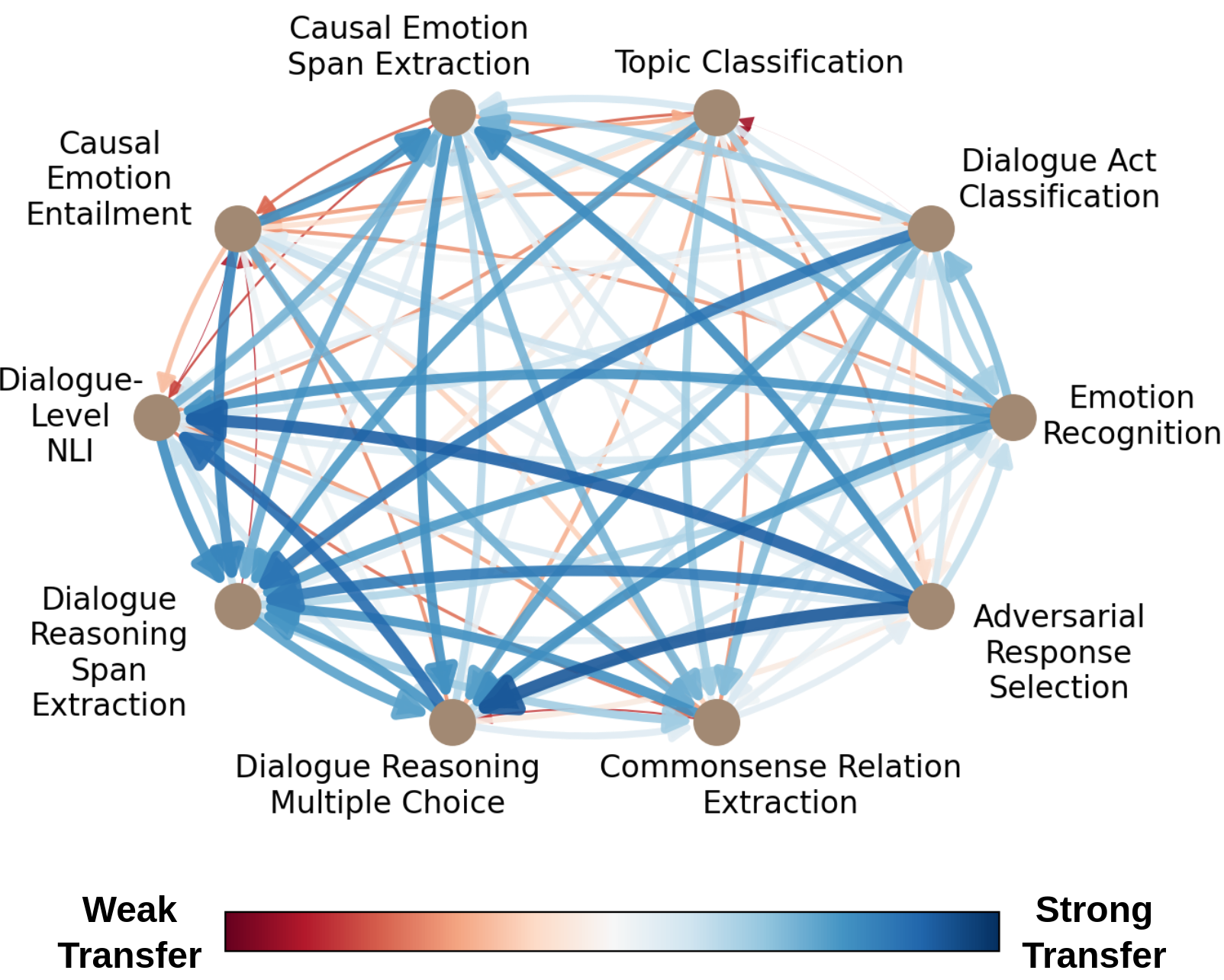
FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
This work introduces FETA, a benchmark for few-sample task transfer in open-domain dialogue, aiming to reduce the need for labeled data in fine-tuning language models. FETA includes two conversation datasets with 10 and 7 tasks, enabling the study of intra-dataset task transfer—transferring knowledge between related tasks without domain adaptation. The paper explores task transfer across 132 source-target pairs using three popular language models and learning algorithms, providing insights into model-specific performance trends. Key findings highlight that span extraction and multiple-choice tasks benefit most from task transfer. Beyond task transfer, FETA offers a resource for future research on model efficiency, pre-training datasets, and learning settings like continual and multitask learning.
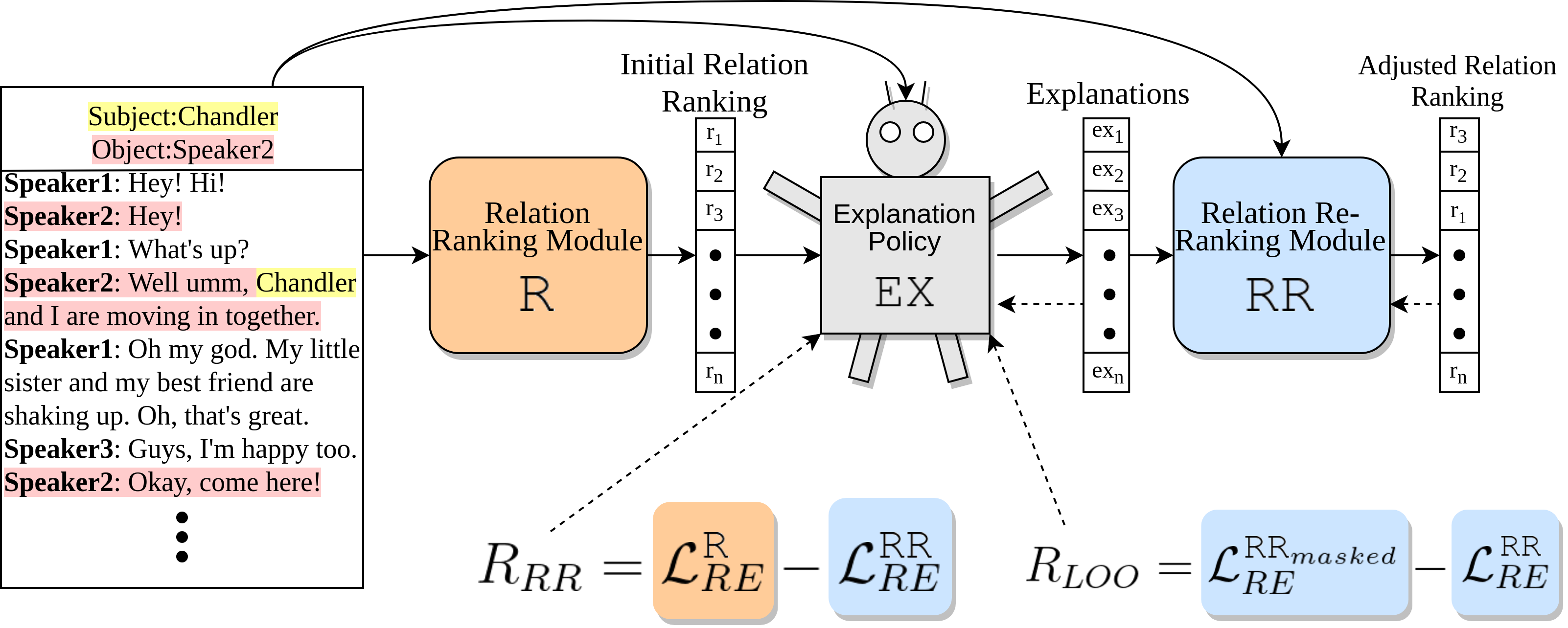
D-REX: Dialogue Relation Extraction with Explanations
This work introduces D-REX, a model-agnostic, policy-guided semi-supervised framework for cross-sentence relation extraction in multi-party conversations, with a focus on explainability. D-REX frames relation extraction as a re-ranking task and provides relation- and entity-specific explanations as an intermediate step. The method outperforms existing models by 13.5% in F1 score on a dialogue relation extraction dataset and is preferred by human annotators 90% of the time over a strong BERT-based model. D-REX offers a simple yet effective approach, advancing both the explainability and accuracy of relation extraction in long-form dialogues.
Contact Me
Email me at "alonalbalak at gmail dot com"